

As mentioned in my previous post one of the projects I wanted to complete over last summer was digitizing as many of the paper processes that I could. One of the largest challenges was finding a way to digitize a major task my student supervisor performs. In the library the student supervisor takes time each week to spot check some of the shelving of the previous week. In order to do this the paper process was as follows:
- When a student assembled a “ready to be shelved” cart they filled out a slip of paper and wrote down 6 random call numbers that appear on the cart. This slip of paper went in to a bin near the computer workstation.
- They would also write their name, date, time and cart number on another slip of paper. This slip stayed with the cart until the cart was completely shelved. Each student who worked on a cart would write down their name on the slip of paper. If one student shelved the entirety of the cart they only had to write their name at the bottom. If multiple people worked on a cart there was a field to indicate where they stopped on the cart.
- Each time a student would head up to the Stacks to shelve they had to fill out their name, date, time and, cart number on a log also kept by the computer workstation.
- The student supervisor would have to match up the the various pieces of paper to figure out who shelved what and then they’d take the slip of paper with the 6 call numbers and go do the spot check. During the spot check they’d write down anything that was out of order and if they did find an error they’d put the slip of paper in a binder that had the various student aides names so they could go back and correct their mistakes.
How do you even begin to digitize this process?
During my first year I had been introduced to Navicat which is piece of database management software (like Microsoft Access). My supervisor had shown me some queries she had built because the reporting tool that comes with our ILS (Integrated Library System) is not very robust. So, while I was thinking about ways to digitize the process it occurred to me I probably could put together a report of some sort. Every time a cart is assembled by a student the cart gets a second check-in. This ensures that all things have been checked-in and catches other statuses a book may be on that need to come off before they head back to the Stacks. Knowing that all these second check-ins were being recorded by the system I was able to build a query based on the items checked-in, the computer they were checked-in on and, a date range. Now, a lot more than just carts get checked in on the computer in the back so I needed a way for the student supervisor to sift through the items relatively easily. I created a google form for my students to fill out:
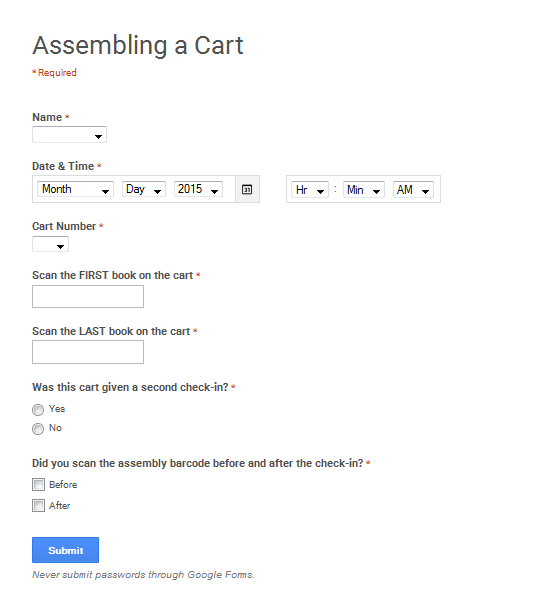
This form gives the student supervisor the barcode information they need to easily find the carts that have been made. In, addition I’ve made my students scan a barcode before and after they check-in a cart. This helps speed up my student supervisor’s process even more by giving them an easily identifiable number to search for in the report that is generated. After the student finish shelving they also fill out an after-shelving form:
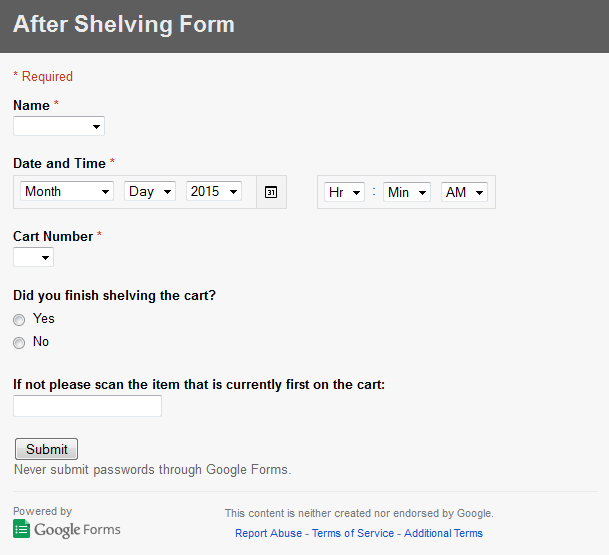
The input from these forms gets dumped in to google spreadsheets that both my student supervisor and I have access to. My student supervisor then has to match up the corresponding information. They look at when carts were made and choose the date range for the query (which they are able to run themselves using some nice and free software that allows you to run basic queries) and then they run the report. They then take the database query output and import it in to our shared google drive folder where they can identify all the carts that are made based on the information in the “Assembled Carts” spreadsheet. After they have identified carts they pull up the “After Shelving” spreadsheet to see who shelved the cart and write their names down. For this last part I let my supervisor choose how they wanted to format things so that when they went spot check it made sense to them. My student supervisor this year color coded the spreadsheet and came up with a system of naming when identifying errors and that seemed to work for them. All that was left to do was grab a tablet (or their phone) and go upstairs and spot check. An, additional advantage to this system of spot checking was the student supervisor now has a complete list of everything on the cart. Rather than leave it up to person assembling the cart to pick 6 random call numbers the student supervisor can be more targeted in their checking. We know certain areas of the Stacks have more problems than others so it makes sense to check those places more often.
In order to get the information back to the student aides about what errors they need to correct I gave them all individual pages on umwstacks.org (which are hidden behind a login) and on each page is an editable spreadsheet so that not only can my student supervisor record the errors, but my student aides could grab tablets and head up in to the Stacks to correct their errors and mark that they fixed them while they are up there. Many opt to write down call numbers still, but quite a few adopted picking up the tablet and heading upstairs to check. This is one part of the process I’m trying to figure out how to make more easily accessible so that more student feel inclined to pick up the device rather than write down a bunch of call numbers on a piece of paper.
We’ve done this new way of spot checking for one academic year and the experiment has been very successful and few fun side benefits have come out of digitizing this process. My student supervisor now spends half the time doing the spot checking that it used to take and now I have the opportunity to expand out that positions task to include more variety and higher-level activities. One of the more fun side benefits that I had not given much thought to is the massive data collection that is a by-product of this process. I now know on average how many carts each week get shelved, when are our busiest weeks, how many items have been shelved, who had the highest accuracy (did I mention my student supervisor was keeping an on-going spreadsheet of student aides accuracy rates?). It was very cool to tell my student during the last week of school that they had shelved over 12,000 items during the semester.
Now that I have all this data it has my brain going about a new approach to student supervisor spot checking and on an even larger scale it has me thinking about the best use of student aide time while they work. I’m going to spend the summer sifting through the data a bit and spend time thinking about better ways to record statistics, do proper analysis (finding rates of accuracy on uneven sample sizes? Got to figure that out) and figure out what data is meaningful to keep recording. I’m excited that the experiment went so well and hopefully with a few more tweaks the system will be even better for this upcoming academic year.
